عبارات منظم Regular Expressions قسمت سوم (آموزش لینوکس LPIC1-101)

عبارات منظم Regular Expressions قسمت سوم (آموزش لینوکس LPIC1-101)
تناوب (Alternation)
از اولین ویژگی هاي عبارات منظم توسعه یافته که درباره آن گفتگو خواهیم کرد، تناوب است.
تناوب مهارتی است که اجازه می دهد تا یک تطبیق از یک مجموعه عبارات اتفاق بیفتد.
درست شبیه یک عبارت براکتی که اجازه می دهد یک کاراکتر از یک مجموعه کاراکترهاي اختصاص یافته مطابقت یابد،
تناوب نیز اجازه می دهد تا تطبیق از یک مجموعه از رشته ها یا دیگر عبارات منظم صورت پذیرد.
براي توضیح آن grep را به همراه echo استفاده خواهیم کرد.
ابتدا یک تطبیق رشته ساده قدیمی را شرح می دهیم.
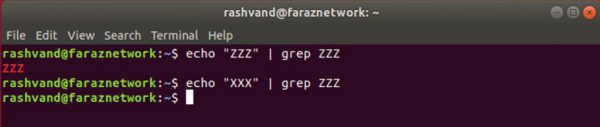
یک مثال واضح که در آن خروجی echo را به داخل grep پایپ کردیم و نتیجه را می بینیم.
زمانی که تطبیق صورت می پذیرد نتیجه را در خروجی می بنیم ولی وقتی تطبیقی وجود ندارد خروجی خالی است.
حالا تناوب را اضافه می کنیم به صورت زیر:
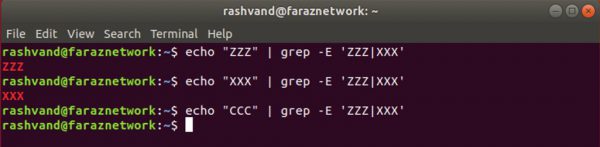
در اینجا عبارت منظم ‘AAA|BBB’ را مشاهده می کنیم که به معنی این است که یکی از دو رشته AAA و یا BBB را تطبیق بده.
از آنجایی که دستور grep را به جاي egrep استفاده می کنیم
و این یک ویژگی توسعه یافته هست، بایستی از گزینه E- استفاده کنیم.
علاوه بر اینها عبارت منظم را درون کوتیشن ها قرار دادیم تا شل (Shell) را از تفسیر متاکاراکتر پایپ به عنوان یک عملگر پایپ منع کنیم
(در اینجا AAA|BBB پایپ بخشی از یک عبارت منظم است).
تناوب محدود به دو نوع انتخاب نیست می توانیم موارد دیگري هم اضافه کنیم به صورت زیر:

به منظور ترکیب تناوب با عناصر عبارت منظم، می توانیم از () به منظور جداسازي تناوب استفاده کنیم:
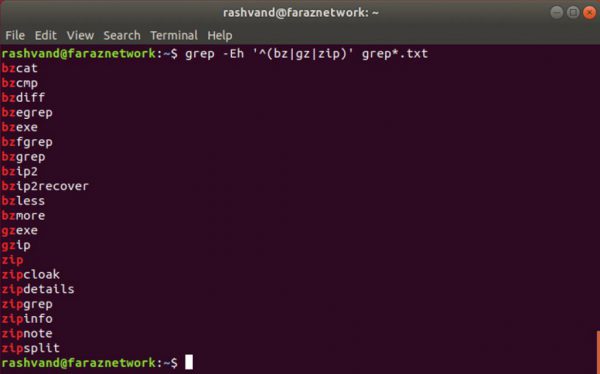
این عبارت اسامی فایل هایی در لیست هاي ما را تطبیق داده که با یکی از موارد bz ,gz و یا zip مطابقت دارند.
اگر پرانتزها را حذف کنیم، معنی عبارت منظم به این صورت تغییر می کند،
یعنی هر نام فایلی را تطبیق بده که با bz شروع شده و یا حاوي gz هست و یا حاوي zip، در صورتی که ما اینگونه نمی خواهیم.
شمارشگرها
عبارات منظم توسعه یافته چندین راه را براي اختصاص تعداد دفعات تطبیق یک عنصر دارند.
با استفاده از شمارشگرهاي مختلف که به بیان آنها خواهیم پرداخت.
شمارشگر علامت سوال (؟) تطبیق یک عنصر صفر بار یا یک بار
شمارشگر (؟) در اصل به این معنی است که عنصر قبلی را اختیاري کن.
فرض کنید می خواهیم یک شماره تلفن را براي اعتبار بررسی کنیم
و در نظر گرفته ایم که یک شماره تلفن معتبر بایستی با یکی از این دو فرم مطابقت داشته باشند:
nnn) nnn-nnnn) و یا nnn nnn-nnnn
چگونه آن را بیان کنیم؟ به این صورت:
![]()
نکته اي که در این عبارت مورد اهمیت است این می باشد که کاراکتري که قبل از علامت سوال ها آمده یعنی () اختیاري است،
با اینکار می توانیم هر دو حالت بالا را بررسی کنیم و هر دو تطبیق داده می شوند.
باز هم توجه داشته باشید از آنجایی که پرانتزها در حالت عادي متاکاراکتر هستند
(در ERE ) آنها را با بک اسلش همراه می کنیم تا به عنوان کاراکترهاي لیترال رفتار کنند.
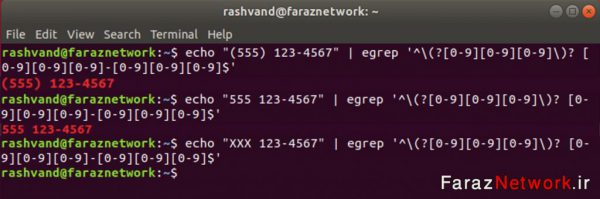
در مورد اول کاراکتر echo شده دارای پرانتز و در مورد دوم کاراکتر echo شده بدون پرانتز است
و در هر دو مورد به دلیل استفاده از شمارشگر (؟) تطبیق صورت می پذیرد.
در مورد سوم به دلیل echo کردن XXX هیچ تطبیقی صورت نمی پذیرد.
شمارشگر ستاره (*) – تطبیق یک عنصر هیچ یا چند مرتبه
شبیه متاکاراکتر علامت سوال (؟)، متاکاراکتر ستاره (*) نیز به منظور دلالت بر یک آیتم اختیاري به کار می رود.
هرچند برخلاف قبلی این بار یک آیتم می تواند تعداد زیادي از دفعات اتفاق بیافتد (نه فقط یکبار).
فرض کنید می خواهیم بفهمیم که آیا یک رشته یک جمله است یا نه؟
یک جمله در زبان انگلیسی با حرف بزرگ آغاز شده سپس شامل تعدادي حروف بزرگ و کوچک و فضاهاي خالی است و در آخر با یک نقطه به پایان می رسد.
براي تطبیق دادن چنین عبارتی می توانیم از عبارتی به صورت زیر استفاده کنیم:
.\*[[:upper:]][[:upper:][:lower:] ]
این عبارت از سه بخش تشکیل شده است:
یک براکت که حاوي کلاس کاراکتري [:upper]
یک براکت حاوي هر دو کلاس کاراکتري [:upper:] و [:lower:]
و یک فاصله و یک نقطه که به همراه بک اسلش نادیده گرفته شده است.
این در حالی است که عنصر دومی با متاکاراکتر * همراه شده
در نتیجه پس از حروف بزرگ ابتدایی در جمله، هر تعداد از حروف بزرگ و کوچک و فاصله که قرار بگیرد باز هم تطبیق صورت می پذیرد.
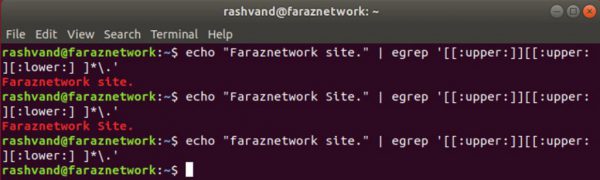
این عبارت دو تست اول را تطبیق داده ولی سومی را تطبیق نمی دهد. چرا؟
به این دلیل که داراي کاراکتر حروف بزرگ ابتدایی و نقطه در پایان نمی باشد.
شمارشگر بعلاوه (+) – تطبیق یک عنصر یک یا چند بار
متاکاراکتر (+) درست شبیه (*) عمل می کند به جز اینکه به حداقل یک نمونه از عنصر قبلی نیاز دارد تا مطابقت صورت پذیرد.
این هم یک عبارت منظم که فقط خطوط حاوي گروهی از یک یا چند کاراکتر الفبایی که با فاصله از هم جدا شده اند را تطبیق می دهد:
![]()
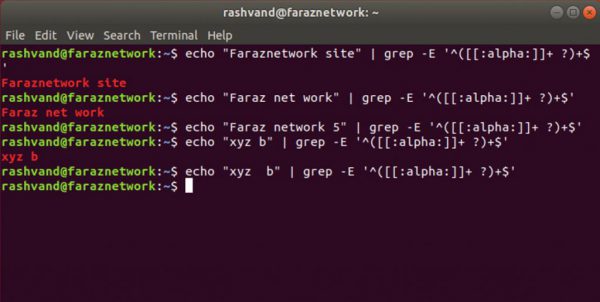
می بینیم که عبارت “Faraz network 5” مطابقت داده نمی شود چون کاراکتر 5 عددي است و الفبایی نیست.
همچنین عبارت “xyz b” نیز مطابقت داده نمی شود چون که بیش از یک فاصله بین دو کاراکتر وجود دارد.
شمارشگر braces {} – تطبیق یک عنصر به تعداد دفعات تعیین شده
متاکاراکترهای { و } به منظور تبیین بیشینه و کمینه تعداد دفعات مورد نیاز تطبیق استفاده می شود.
آنها را می توان به چهار شیوه مختلف به کار گرفت که در جدول زیر مشاهده می کنید:

اکنون آن را امتحان می کنیم:
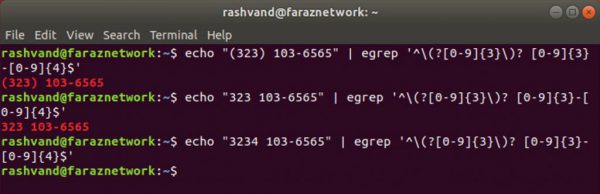
همانطور که می بینیم به جاي تایپ چند حرف اینبار فقط تعداد دفعات تکرار کاراکتر را در داخل { } قرار می دهیم.
بکارگیري عبارات منظم
خب تا اینجاي کار درباره عبارات منظم بسیار صحبت کردیم و مثال هاي تمرینی زیادي را اجرا نمودیم.
اکنون با استفاده از این دستوراتی که یاد گرفتیم می خواهیم چند مثال کاربردي را انجام دهیم:
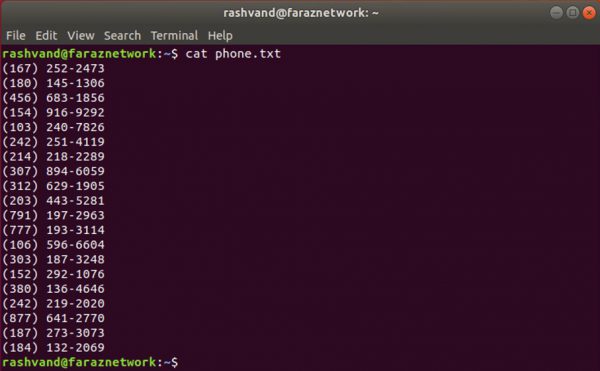
اعتبارسنجی یک لیست تلفن با grep
در مثال اخیر، به یک شماره تلفن نگاهی انداختیم و شماره تلفن را براي فرمت مناسب بررسی کردیم.
یک سناریو واقعی تر، بررسی کردن یک لیست از شماره هاي تلفن است.
پس بیایید یک لیست ایجاد کنیم.
این کار را با خط فرمان انجام می دهیم.

این دستور یک فایل با نام phone.txt را ایجاد می کند که حاوي 20 شماره تلفن است.
هر زمان که این دستور تکرار شود 20 شماره دیگر به لیست اضافه می شود.
همچنین می توانیم مقدار 20 را تغییر دهیم تا تعداد کمتر یا بیشتري شماره ایجاد کنیم:
یافتن نام هاي بدترکیب فایل با دستور find
دستور find از یک تست خاص، بر پایه عبارات منظم پشتیبانی می کند.
به هنگام استفاده از find بجاي grep در عبارات منظم موضوعی مهم را بایستی در نظر بگیرید.
چه موضوعی؟ اینکه grep خطی را که حاوي مورد مطابقت داده شده با عبارت منظم است را چاپ می کند.
ولی در find بایستی نام مسیر دقیقا با عبارت منظم مطابقت پیدا کند.
در مثال زیر:
از find به همراه یک عبارت منظم استفاده می کنیم تا هر نام مسیري که حاوي کاراکتري از اعضاي زیر نیست را پیدا کنیم:
[-_%-a-Za-Z9]
یک چنین جستجویی نام هاي مسیر را که حاوي فضاهاي جاسازي شده و کاراکترهاي محتمل دیگر هست را آشکار می سازد:

اجراي یک مطابقت دقیق یک نام مسیر به صورت کامل، از *. در پایان هر عبارت استفاده کردیم تا هیچ یا چند نمونه از هر کاراکتر را تطبیق دهد.
در وسط عبارت از یک عبارت براکتی نفی شده حاوي مجموعه اي از کاراکترهاي نام مسیر قابل قبول استفاده می کنیم.
جستجو براي فایل ها با استفاده از locate
هر دو نوع عبارات منظم پایه (گزینه regexp–) و توسعه یافته (گزینه regex–) را پشتیبانی می کند.
با استفاده از آن می توانیم بسیاري از عملیات هایی که قبلا بر روي فایل هاي dirlist انجام می دادیم را انجام دهیم.

با استفاده از تناوب، جستجویی براي نام هاي مسیري که حاوي bin/bz ,bin/gz یا bin/zip/ هستند را انجام می دهیم.
جستجوی متن با less و vim
دستور less و vim متد جستجوي یکسانی را براي متن به اشتراك می گذارند.
فشار دادن کلید / به همراه یک عبارت منظم یک جستجو را انجام خواهد داد.
ما از less به منظور نمایش فایل phone.txt استفاده می کنیم
و سپس عبارت اعتبارسنجی را جستجو می کنیم:

جهت مشاهده دوره های آموزشی بر روی این لینک کلیک نمایید.
جدیدترین اخبار مجموعه فراز نتورک را در این صفحه اجتماعی دنبال کنید.
نویسنده: موسی رشوند




دیدگاهتان را بنویسید
برای نوشتن دیدگاه باید وارد بشوید.