عبارات منظم Regular Expressions قسمت دوم (آموزش لینوکس LPIC1-101)

عبارات منظم Regular Expressions قسمت دوم (آموزش لینوکس LPIC1-101)
عبارات براکت و کلاس هاي کاراکتر
علاوه بر مطابقت هر کاراکتري در یک موقعیت در عبارت منظم، می توانیم یک کاراکتر را از یک مجموعه کاراکتر تعیین شده تطبیق دهیم.
چگونه؟ با استفاده از عبارت هاي براکت.
با عبارت هاي براکت (Bracket Expressions) می توانیم:
یک مجموعه از کاراکترها (شامل کاراکترهایی که غیر از این به عنوان متاکاراکترها تفسیر می شوند) را براي تطبیق اختصاص دهیم.
در این مثال با استفاده از یک مجموعه دو کاراکتري، هر خطی که حاوي رشته bzip یا gzip هست را تطبیق می دهیم.
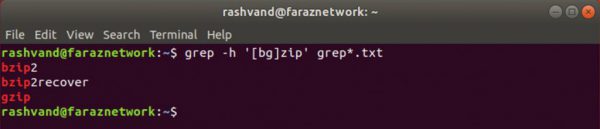
یک مجموعه ممکن است حاوي هر تعداد از کاراکترها و متاکاراکترها باشد که وقتی در داخل براکت ها قرار می گیرند معنی خود را از دست می دهند.
هرچند دو مورد وجود دارد که در آنها متاکاراکترها درون عبارات براکت استفاده شده اند و معناي متفاوتی دارند.
اولین آنها کاراکتر (^) هست که به منظور نشان دادن نفی به کار می رود
و دومین آنها کاراکتر (-) هست که به منظور نشان دادن یک محدوده کاراکتري به کار می رود.
کاراکتر نفی (Negation)
اولین کاراکتر در یک عبارت براکت یک کاراکتر (^) هست و بقیه کاراکترها مجموعه کاراکترهایی هستند که نبایستی در موقعیت کاراکتري داده شده قرار بگیرند.
این کار را با ویرایش مثال قبلی خود انجام می دهیم:
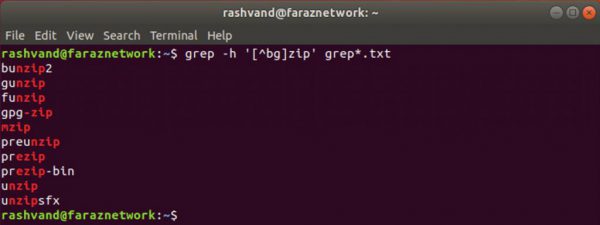
با فعال شدن نفی، ما لیستی از فایل هایی که حاوي رشته zip هستند را به جز آنهایی که داراي کاراکتر b یا g هستند را دریافت می کنیم.
توجه کنید که فایل zip پیدا نشد.
یک مجموعه کاراکتر نفی شده هنوز نیازمند یک کاراکتر در موقعیت داده شده است ولی کاراکتر نباید عضوي از مجموعه کاراکتر نفی شده باشد.
کاراکتر (^) فقط در صورتی نفی را فراخوانی می کند که اولین کاراکتر در داخل یک عبارت براکت باشد.
در غیر این صورت مفهوم خاص خود را از دست می دهد و به یک کاراکتر معمولی در یک مجموعه تبدیل می شود.
محدوده هاي معمول کاراکتر (Character Ranges)
اگر بخواهیم یک عبارت منظم را ایجاد کنیم که در آن هر فایل را در لیست پیدا کند که نام آنها با یک حرف بزرگ شروع می شود،
می توانیم به صورت زیر عمل کنیم:
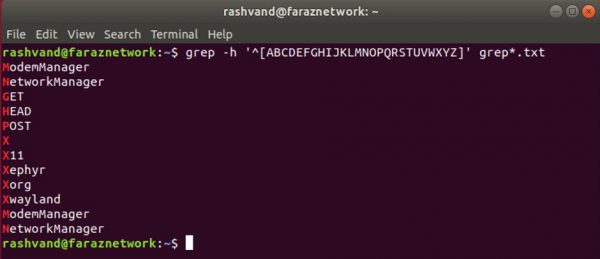
چرا این قدر شلوغ ! فقط کافی است محدوده مورد نظر را با علامت (-) از هم جدا کنیم به صورت زیر:

با به کار بردن محدوده سه کاراکتري، می توانیم 26 کاراکتر را خلاصه کنیم.
هر محدوده از کاراکترها را می توان به این شیوه بیان کرد،
شامل محدوده هایی مثل این عبارت که همه نام هاي فایلی که با حروف و اعداد شروع می شوند را شامل می شود:

در محدوده هاي کاراکتري، می بینیم که کاراکتر دش (-) به صورت ویژه رفتار می کند،
پس چگونه یک کاراکتر دش را در عبارت براکت قرار می دهیم؟
به این صورت، آن را اولین کاراکتر در عبارت قرار می دهیم.
مورد زیر را فرض کنید:

این مورد هر نام فایلی که حاوي یک حرف بزرگ هست را تطبیق می دهد.
ولی از سوي دیگر:

این مورد هر نام فایلی که حاوي یک علامت دش (-)، یک حرف A بزرگ و یک حرف Z بزرگ هست را تطبیق می دهد.
کلاس هاي کاراکتر POSIX
محدوده هاي معمول کاراکتر به سادگی قابل درك هستند و براي حل سریع مشکلات به منظور اختصاص مجموعه اي از کاراکترها موثر هستند.
متاسفانه آنها همیشه راهگشا نیستند.
وقتی که قادر به استفاده از آنها نباشیم بایستی چه کار کنیم؟
به درس هاي قبل که سري بزنیم مشاهده می کنیم که به صورت گسترده از وایلدکاردها به منظور اجراي بسط نام مسیر استفاده کردیم.
در آن مباحث گفتیم که محدوده هاي کاراکتري را می توان به شیوه اي استفاده کرد
تقریبا شبیه روشی است که در عبارات منظم استفاده می کنیم ولی مشکل اینجاست

بنا به توزیع لینوکسی که استفاده می کنید، لیست فایل هاي متفاوتی را دریافت خواهید کرد و حتی ممکن است یک لیست خالی را دریافت کنید.
این مثال در توزیع اوبونتو اجرا شده است (این دستور نتایج دلخواه را ایجاد کرد. یک لیست از فایل هایی که نامشان با حروف بزرگ آغاز می گردد.
ولی دستور زیر نتایج کاملا متفاوتی را به ما نشان خواهد داد !!)
فقط بخشی از نتایج نشان داده شده است:
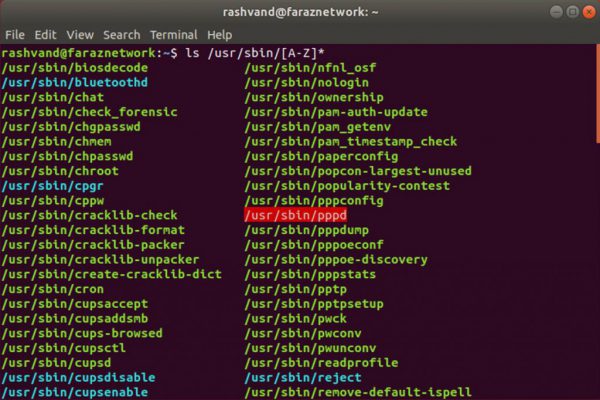
خب ممکنه سوال بپرسید که چرا خروجی این قدر طولانی است؟
داستان از این قرار است:
وقتی که در ابتدا یونیکس توسعه یافت، فقط کاراکترهاي ASCII را می شناخت و این ویژگی در اثر همین شناخت پایین بوجود آمده است.
در کاراکترهاي ASCII32 کاراکتر اول کدها را کنترل می کنند
(کاراکترهایی مثل tabs ,backspace ,carriage return) کاراکترهاي بعدي یعنی شماره هاي 32 تا 63 شامل کاراکترهاي چاپی، بیشتر کاراکترهاي نقطه گذاري و شماره هاي صفر تا نه هستند.
کاراکترهاي بعدي هم یعنی شماره هاي 64 تا 95 شامل حروف بزرگ و برخی دیگر از نشانه هاي نقطه گذاري هستند.
در نهایت بخش آخر یعنی کاراکترهاي 96 تا 127 شامل حروف کوچک و باز هم نشانه هاي دیگر نقطه گذاري هستند.
بر اساس این ترتیب سیستم هایی که از ASCII استفاده می کنند،
از یک ترتیب تلفیقی به این شکل استفاده می کنند:
ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz
و همانطور که می دانید این ترتیب با آنچه به صورت عادي در ترتیب دیکشنري قرار دارد متفاوت است.
:aAbBcCdDeEfFgGhHiIjJkKlLmMnNoOpPqQrRsStTuUvVwWxXyYzZ
همانطور که یونیکس گسترش یافت نیاز به رشد براي پشتیبانی از کاراکترهایی که در زبان انگلیسی نیستند پیدا شد.
جدول ASCII گسترش یافت تا از 8 بیت کامل استفاده کند و کاراکترهاي شماره 128تا 255 به آن اضافه شدند تا زبان هاي زیاد دیگري را پشتیبانی کند.
براي پشتیبانی از این ویژگی استانداردهاي POSIX مفهومی با نام locale را معرفی کردند.
لوکاله را می توان تنظیم کرد تا مجموعه اي از کاراکترهاي ناحیه اي خاص را انتخاب کند.
تنظیمات زبان سیستم خود را می توانیم با این دستور مشاهده کنیم:

با این تنظیم، اپلیکیشن هاي سازگار با POSIX به جاي استفاده از ترتیب ASCII از یک ترتیب تلفیقی دیکشنري استفاده خواهند کرد.
این مسئله رفتار بالا را توضیح می دهد.
براي حل این مشکل استاندارد POSIX تعدادي از کلاس هاي کاراکتري را دارد که محدوده هاي مفید کاراکتري را فراهم می کند.
جدول زیر این کلاس ها را توصیف می کند:
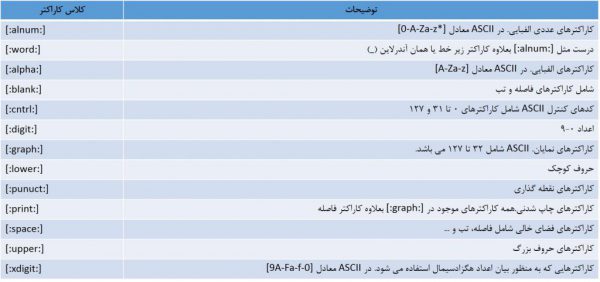
حتی با وجود کلاس هاي کاراکتري، هنوز هیچ راه مناسبی براي بیان محدوده هاي بخشی مثل [A-M] وجود ندارد.
با استفاده از کلاس هاي کاراکتري می توانیم لیست دیکشنري خود را تکرار کنیم و نتایج بهبود یافته اي را دریافت کنیم:
به یاد داشته باشید که هرچند این مثالی از یک عبارت منظم نیست ولی در عوض بسط نام مسیر را انجام می دهد.
به این دلیل این مثال را بیان کردیم زیرا کلاس هاي کاراکتري POSIX براي هر دو منظور استفاده می شوند.
POSIX پایه در برابر عبارات منظم توسعه یافته
درست زمانی که فکر می کنیم موضوع گیج کننده نیست،
می فهمیم که POSIX اجراهاي عبارات منظم را به دو نوع تقسیم می کند:

عبارات منظم ساده (Basic Regular Expressions(BRE و عبارات منظم توسعه یافته (Extended Regular Expressions(ERE
ویژگی هایی که ما تا اینجا پوشش دادیم توسط هر اپلیکیشنی که با POSIX و اجراهاي BRE سازگار هست پشتیبانی می شود.
برنامه grep یکی از این اپلیکیشن هاست.
چه تفاوتی بین BRE و ERE وجود دارد؟
موضوع بر سر متاکاراکترهاست.
با BRE این متاکاراکترها تشخیص داده می شوند:
^$* [ ] . دیگر کاراکترها به عنوان لیترال ها در نظر گرفته می شوند.
در حالی که با ERE کاراکترهاي { } ( )? +| و توابع آن ها اضافه می شوند.
هرچند کاراکترهاي {} () در صورتی که با بک اسلش نادیده گرفته شوند، به عنوان متاکاراکترهاي BRE رفتار می کنند
در حالی که در ERE نادیده گرفتن (Escaping) هر متاکاراکتري با بک اسلش باعث می شود که به عنوان لیترال ها رفتار کند.
از آنجایی که ویژگی هایی که ما در بخش بعدي درباره آنها صحبت می کنیم بخشی از ERE هستند،
نیاز به استفاده از نوع متفاوتی از grep داریم.
به صورت معمول اینکار با برنامه egrep انجام می شود
ولی نسخه GNU دستور grep نیز عبارات منظم توسعه یافته را بوسیله اضافه کردن گزینه E- پشتیبانی می کند.
جهت مشاهده دوره های آموزشی بر روی این لینک کلیک نمایید.
جدیدترین اخبار مجموعه فراز نتورک را در این صفحه اجتماعی دنبال کنید.
Regular Expressions – نویسنده: موسی رشوند
Regular Expressions قسمت دوم




دیدگاهتان را بنویسید
برای نوشتن دیدگاه باید وارد بشوید.