بررسی اجزاء اصلی کارت گرافیک سرورها

بررسی اجزاء اصلی کارت گرافیک سرورها
- برد اصلی
- پردازنده یا GPU
- حافظه یا Memory
- Memory BUS
- Memory Clock
- مقایسه پردازندههای گرافیکی GPU NVIDIA Tesla/Quadro با NVIDIA GeForce
- (FP64 (Floating Point
- پشتیبانی نرمافزارهای کاربردی
- پشتیبانی سیستمعامل
- کارایی توان مصرفی
- Direct memory access) DMA)
- (CUDA (Compute Unified Device Architecture
- GPU Direct RDMA
- Hyper-Q
- نظارت و مدیریت تواناییهای GPU
- فلاپ یا ترافلاپس چیست؟
- محاسبه میزان فلاپس در یک GPU:
- بررسی پردازندههای گرافیکیGPU NVIDIA Tesla P یا همان سری Pascal
- بررسی پردازندههای گرافیکی GPU NVIDIA Tesla V یا همان سری Volta
- کارت گرافیک NVIDIA Tesla K40
- کارت گرافیک NVIDIA Tesla K80
- کارت گرافیک NVIDIA Tesla M60
- NVIDIA Tesla P100
- AMD Radeon Pro V340
- کارت گرافیک سروری AMD FirePro W9100
- قدرتمندترین کارت گرافیک AMD برای کارهای حرفه ای و سرور با 5 ترافلاپ قدرت پردازشی
برد اصلی
پردازنده یا GPU
-
حافظه یا Memory:
حافظه بر روی کارت، باعث می شود که پردازشگر برای به دست آوردن اطلاعات مورد نیاز، کمتر به حافظه اصلی مراجعه کند
در اینصورت، سرعت پردازش تصاویر بالا می رود.
سرعت پردازنده (Core Clock) کارت گرافیک، مهمترین عامل افزایش کارائی یک کارت گرافیک است.
مشابه پردازنده کامپیوترهاست.
به سرعت Render و تعداد پیکسل هایی که می تواند پردازش نماید بستگی دارد.
-
Memory BUS:
به عرض مسیر انتقال دیتا در حافظه گفته می شود.
هرچه این عرض بیشتر باشد (256 بیت، 128 بیت، 64 بیت) سرعت جریان دیتا در رم بالاتر بوده
و به طبع قدرت کارت بالاتر رفته و بازی ها و برنامه ها روانتر اجرا می شوند.
-
Memory Clock:
به سرعت حرکت دیتا در حافظه کارت گرافیک گفته می شود.
کارت های گرافیک، دارای یک تراشه کوچک بنام BIOS هستند.
BIOS وظیفه راه اندازی اولیه و تست کارت گرافیک را برعهده دارد.
Frames Per Second) FPS) یا همانند Frame Rate فریم هایی که در هر ثانیه نمایش داده می شود.
معمولا این مقدار برای پخش ویدئو ۳۰ فریم بر ثانیه است
با اجرای فریم های بیشتر، تصاویر سریع تر و با وضوح بهتری بدست می آید.
-
SLI-Support مخفف عبارت Scalable Link Interface است.
شرکت NVIDIA این روش را برای توسعه کارتهای گرافیکی خود ابداء نموده است.
با استفاده از این تکنولوژی می توان دو یا چند کارت گرافیک را در کنار هم نصب و یک خروجی بسیار قوی و با کیفیت دریافت نمود.
سرورها هم به مانند PC ها به کارت گرافیک نیاز دارند.
با توجه به اینکه سرورها عموما کارهای پردازشی سنگین انجام می دهند نیاز به Processor قدرتمندی دارند
و کمتر به کارت های گرافیک حرفه ای نیاز پیدا می کنند
AMD و NVIDIA از شرکت هایی هستند که کارت گرافیک حرفه ای برای سرورها را تولید می کنند

از شرکت NVIDIA می رویم سراغ کارت های گرافیک نوع TESLA که مناسب برای دیتا سنترهاست.

مقایسه پردازندههای گرافیکی GPU NVIDIA Tesla/Quadro با NVIDIA GeForce
تمام GPU های NVIDIA از محاسبات عمومی (GPGPU) پشتیبانی می کنند،
اما همه graphical processing units) GPU)ها عملکرد مشابهی ندارند.
GPU های سری GeForce (به خصوص GTX Titan) ممکن است برای کسانی که از برنامههای کاربردی مبتنی بر GPU استفاده میکنند، مورد جذابیت قرار گیرد.
با این حال، عاقلانه است که تفاوت بین محصولات را در نظر بگیرید.
ویژگیهای زیادی در GPU های حرفهای Tesla و Quadro وجود دارد.
(FP64 (Floating Point
بسیاری از برنامهها نیاز به محاسبات ریاضی با دقت بالا دارند.
یکی از گلوگاههای بالقوه در مورد کارایی GPU انتظار برای انتقال اطلاعات به GPU است.
خصوصا زمانی که چندین پردازنده گرافیکی به طور موازی با یکدیگر کار میکنند.
انتقال سریع دادهها به طور مستقیم، باعث عملکرد سریعتر برنامه میشود.
GPU های GeForce از طریق PCI-Express متصل میشوند که دارای حداکثر توان خروجی تئوری 16 گیگابایت بر ثانیه است.
پردازندههای NVIDIA Tesla / Quadro با استفاده از NVLink قادر به اتصال بسیار سریعتر هستند.
اتصال NVLink در سری “پاسکال” به هر یک از پردازندههای گرافیکی اجازه میدهد
تا با سرعت 80 گیگابایت بر ثانیه (160 گیگابایت بر ثانیه در حالت دو طرفه) ارتباط برقرار کنند.
اتصال NVLink 2.0 در سری “Volta” اجازه میدهد تا هر GPU با نرخ 150 گیگابایت بر ثانیه (300 گیگابایت بر ثانیه در حالت دوطرفه) ارتباط برقرار کند.
اتصال NVLink بین GPU ها و همچنین بین CPU ها و GPU ها در پلتفرم Open POWER پشتیبانی میشود.
تنها GPU هایTesla و Quadro از NVLink پشتیبانی میکنند.

پشتیبانی نرمافزارهای کاربردی
بیشتر نرمافزارهای حرفهای فقط رسما از GPU هایNVIDIA Tesla وQuadro پشتیبانی میکنند.
استفاده از GeForce در این نرمافزارها ممکن است امکان پذیر باشد، اما توسط تولیدکننده نرمافزاری پشتیبانی نخواهد شد.
پشتیبانی سیستمعامل
اگر چه درایورهای GPU های NVIDIA متنوع هستند، اما درایورهای GeForce برای سیستمعاملهای ویندوز سرور وجود ندارد.
پردازندههای گرافیکی GeForce تنها در ویندوز 7، ویندوز 8 و ویندوز 10 پشتیبانی می شوند.
گروههایی که از ویندوز سرور استفاده میکنند، باید محصولات حرفهای تسلا و Quadro را انتخاب کنند.
درایورهای لینوکس، از تمام پردازندههای گرافیکی NVIDIA پشتیبانی میکنند.
کارایی توان مصرفی
پردازندههای گرافیکی GeForce برای استفاده در بازیهای کامپیوتری طراحی شدهاند.
در مقابل GPU های Tesla برای استفاده در مقیاس بزرگ طراحی شدهاند که در آن بهرهوری از توان مهم است.
این باعث میشود که GPU های Tesla برای کاربردهای بزرگ مناسب واقع شوند.
Direct memory access) DMA)
دسترسی مستقیم به حافظه (DMA) در یکGPU برای انتقال سریع داده بین حافظه سیستم و حافظه گرافیکی استفاده میشود.
عملکرد آن برای کارایی GPU حیاتی است.
محصولات GeForce دارای یک موتور DMA است که می تواند دادهها را در یک جهت در هر زمان انتقال دهد.
محصولات Tesla دارای دو موتور DMA هستند.
میتوانند همزمان دادهها را به GPU وارد و یا از آن خارج کند.
(CUDA (Compute Unified Device Architecture
یک سکوی پردازش موازی است که توسط شرکت انویدیا بهوجود آمده است
به توسعه دهنده گان نرمافزار اجازه میدهد تا از یک GPU که ویژگی CUDA-enabled دارد برای هدف پردازش استفاده کنند،
رویکردی که GPGPU شناخته میشود.
کودا به توسعهدهنده گان امکان دسترسی مستقیم به حافظه را میدهد.
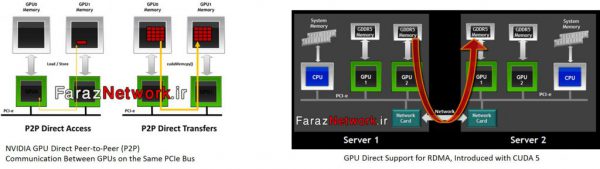
GPU Direct RDMA
فن آوری GPU-Direct NVIDIA اجازه می دهد تا سرعت انتقال داده بین GPU ها به طور قابل توجهی بهبود یابد.
با استفاده از این تکنولوژی، قابلیتهای مختلف ارائه میگردد که مهمترین آنها قابلیت Remote Direct Memory Access) RDMA) است.
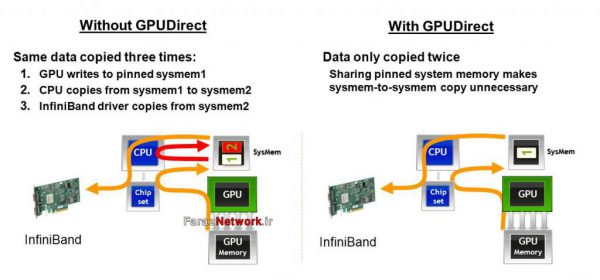
به طور سنتی، ارسال اطلاعات بین GPU های یک کلاستر، با بار 3 کپی کردن انجام میشود
(یک بار به حافظه سیستم GPU، یک بار به حافظه سیستم CPU و یک بار به حافظه درایور InfiniBand)
GPU Direct RDMA کپی به حافظه سیستم را حذف می کند و اجازه میدهد GPU به طور مستقیم از طریق InfiniBand به یک سیستم دیگر داده ارسال کند.
در عمل، این موجب کاهش 67 درصدی تاخیر و افزایش 430 درصدی پهنای باند برای پیامهای کوچک MPI شده است.
در نسخه 8 Quadro، انویدیا GPU Direct RDMA ASYNC را معرفی کرد که اجازه میدهد
پردازنده گرافیکی بدون هیچ گونه تعامل با CPU انتقالات RDMA را انجام دهد.
پردازندههای GeForce از GPU-Direct RDMA پشتیبانی نمیکنند.
تنها شکلی از GPU-Direct که روی کارتهای GeForce پشتیبانی می شود، GPU Direct P2P است.
این اجازه انتقال سریع در یک کامپیوتر واحد را میدهد، اما برای برنامههایی که به صورت توزیع شده روی سرورهای متعدد اجرا می شود، هیچ کمکی نمیکند.
GPU های Tesla به طور کامل از GPU Direct RDMA و سایر قابلیتهای دیگر GPU Direct پشتیبانی می کنند.
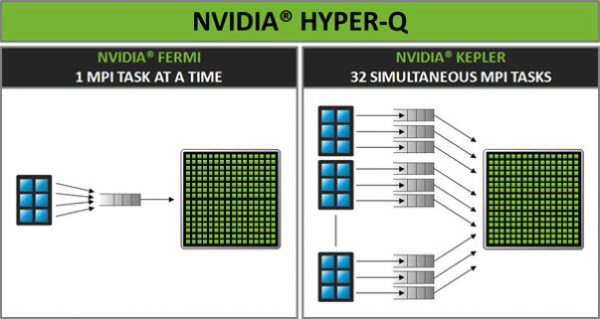
Hyper-Q
Hyper-Q Proxy برای (MPI (Message Passing Interface و CUDA اجازه می دهد که چندین نخ پردازشی یا چند پردازنده روی یک GPU واحد کار کنند.
این ویژگی برای برنامههای موازی نوشته شده با MPI کارایی دارد، زیرا این کدها برای استفاده از هستههای پردازنده طراحی شدهاند.
فراهم آوردن امکان پذیرش کار از هر یک از پروسههای MPI در حال اجرا بر روی یک سیستم می تواند به افزایش قابل توجه عملکرد GPU منجر شود.
همچنین میتواند فرایند افزودن استفاده از توان پردازشی GPU به یک برنامه موجود را تسهیل نماید.
با این حال، تنها شکل Hyper-Q که در GPU های GeForce پشتیبانی میشود، Hyper-Q برای CUDA Streams است.
این ویژگی اجازه میدهد تا GeForce محاسبات موازی را از هستههای CPU دریافت و اجرا کند،
اما برنامههای در حال اجرا روی چند کامپیوتر، قادر به استفاده از یک GPU نخواهند بود.
نظارت و مدیریت تواناییهای GPU
بسیاری از پارامترهای نظارتی و قابلیتهای مدیریت GPU (که هنگام استفاده از چندین سیستم GPU حیاتی هستند)
تنها در پردازندههای Tesla حرفهای پشتیبانی میشوند.
ویژگیهای نظارتی که در GPU های GeForce پشتیبانی نمیشوند.
/ NVidia-SMI NVIDIA Management Library) NVML):
برای نظارت و مدیریت وضعیت و قابلیتهای هر GPU، این ویژگی امکان اتصال GPU به تعدادی از برنامههای کاربردی و ابزارهای نظارتی مانند Ganglia ،Perl و Python را فراهم میآورد.
OOB:
نظارت سختافزاری از طریق Intelligent Platform Management Interface) IPMI) اجازه میدهد تا سیستم بر سلامتGPU نظارت کند،
سرعت فن را برای خنکسازی مناسب دستگاه تنظیم کند و در صورت مشاهده مشکل پیغام هشدار ارسال نماید.
InfoROM:
(دادههای دائمی برای پیکربندی و حالت) دادههای تکمیلی برای هر GPU ارائه میدهد.
ابزار NVHealthmon:
برای مدیران کلاستر یک ابزار آماده برای نظارت بر وضعیت GPU فراهم میکند.
TCC اجازه می دهد که GPU ها تنها برای حالت نمایش یا تنها برای حالت پردازش تنظیم شوند.
ECC (تشخیص و اصلاح خطای حافظه)
ابزارهای مدیریت کلاستر از قابلیتهای ارائه شده توسط NVIDIA NVML بهره میبرند.
تقریبا 60 درصد از این قابلیتها در GeForce وجود ندارد.
فلاپ یا ترافلاپس چیست؟
در واقع کلمه FLOPS، مخفف عبارتFloating Point Operation per Second نقطه اوج توان گرافیکی است
که با آن، مقدار ظرفیت پردازشی یک GPU را محاسبه میکنند.
محاسبه میزان فلاپس در یک GPU:
ابتدا تعداد هستههای Shader یک GPU را با سرعت هستههای پردازشی آن ضرب کرده و پاسخ را در عدد 2 ضرب میکنیم.
این چنین میزان فلاپس یک کارت گرافیک یا یک پردازنده گرافیکی به دست میآید
و دلیل این که پاسخ را در 2 ضرب میکنیم،
این است که یک چیپ گرافیکی، می تواند دو کار بالا، یعنی بخش Shader ها و هسته های پردازشی را با هم و به صورت همزمان انجام دهد
بررسی پردازندههای گرافیکیGPU NVIDIA Tesla P یا همان سری Pascal
GPU های “Pascal” معماری نسلهای قبلی یعنی “Kepler” و “Maxwell” را بهبود میبخشند.
ویژگیهای مهم موجود در معماری GPU های سری Pascal عبارتند از:
- عملکرد HPC فوقالعاده:
با عملکرد 5.3 ترافلاپس در حالت دقت مضاعف و 10.6 ترافلاپس برای دقت ساده در محاسبات ممیز شناور.
- NVLink:
باعث افزایش 5 برابری پهنای باند بین GPU های Tesla و بین GPU ها و CPU های سیستم میشود (در مقایسه با PCI-Express)
- حافظه HBM2 با پهنای باند بالا:
بهبود عملکرد حافظه تا سه برابر در مقایسه با GPU های نسل قبل
- حافظه یکپارچه پیشرفته:
اجازه می دهد تا برنامههای کاربردی GPU به طور مستقیم به حافظه تمام GPU ها و همچنین تمام حافظه سیستم (تا 512 ترابایت) دسترسی پیدا کنند.
- تا 4 مگابایت حافظه L2:
در GPU Pascal (در مقایسه با 1.5 مگابایت درKepler و 3 مگابایت در Maxwell)
- حافظههای ECC با قابلیت تشخیص و تصحیح خطا:
مطابق با یک نیاز حیاتی برای محاسبه با دقت و قابلیت اطمینان در مراکز داده و مراکز Cloud
- بهرهوری انرژی:
توان اسمی GPU های پاسکال به ازای هر وات توان مصرفی، تقریبا دو برابر پردازندههای گرافیکی Kepler است.
- واحدهای SM کارآمد:
معماری پاسکال تعداد رجیسترهای هر نخ (Thread) را دو برابر میکند.
- اولویت محاسباتی (Compute Preemption):
اجازه می دهد تا فعالیتهای با اولویت بالا فعالیتهای در حال اجرا را متوقف سازند.

بررسی پردازندههای گرافیکی GPU NVIDIA Tesla V یا همان سری Volta
GPU های “Volta” معماری نسل قبلی یعنی “Pascal” را بهبود میبخشند. به حافظه 32 گیگابایتی ارتقا یافتند.
ویژگیهای مهم موجود در معماری GPU های سری Volta عبارتند از:
- عملکرد HPC فوقالعاده با عملکرد 7.8 ترافلاپس در حالت دقت مضاعف و 15.7 ترافلاپس برای دقت ساده در محاسبات ممیز شناور.
- اجرای همزمان دستورات FP32 و INT32 که عملکرد کلی پردازنده گرافیکی را بهبود میبخشد
- NVLink باعث افزایش 8 تا 10 برابری پهنای باند بین GPU های Tesla و بین GPU ها و CPU های سیستم میشود (در مقایسه با PCI-E)
- حافظه HBM2 با پهنای باند بالا بهبود عملکرد حافظه تا سه برابر در مقایسه با GPU های نسل قبل
- حافظه یکپارچه پیشرفته اجازه می دهد تا برنامههای کاربردی GPU به طور مستقیم به حافظه تمام GPU ها و همچنین تمام حافظه سیستم (تا 512 ترابایت) دسترسی پیدا کنند.
- حافظه ECC محلی بدون هیچ گونه سرباری، خطاهای حافظه را شناسایی و اصلاح میکند.
- ترکیب Cache L1 و حافظه اشتراکی، انعطاف پذیری بیشتر و عملکرد بالاتر از Pascal را فراهم می کند.

کارت گرافیک NVIDIA Tesla K40
کارت گرافیک سرور NVIDIA مدل K40 دارای توان عملیاتی بالا با حداکثر مصرف برق 235 وات است.
این کارت گرافیک با 12 گیگابایت حافظه از نوع GDDR5 SDRAM مجهز به حداکثر پهنای باند حافظه 288 گیگابایت بر ثانیه بوده که قادر به انتقال داده هاست.
کارت گرافیک NVIDIA از درگاه ارتباطی PCI Express 3.0 x16 برخوردار است.
تراشه شتابدهنده گرافیک NVIDIA به نام Tesla K40 جزء سریعترین پردازنده مکمل یا Coprocessor در زمینه محاسبات ابری است.
محاسبات سنگین و پردازشهای پیچیده علمی و ریاضی به آنها سپرده میشود.
در طراحی این تراشه تسلا از نسخه بهبود یافته معماری NVIDIA Kepler استفاده شده است.
سرعت تراشه Tesla K40 برابر با 1.43 ترافلاپس است.
سرعت کلاک پایه در هستههای Tesla K40 برابر با ۷۴۵ مگاهرتز است.
اما بر حسب نیازهای محاسباتی کاربران، میتواند تا ۸۱۰ یا ۸۷۵ مگاهرتز افزایش یابد.
نسل قبلی این کارت گرافیک یعنی Tesla K20 از تراشه و فناوری GK110 استفاده میکرد که مزیت کلیدیTesla K20 محسوب میشود.
که NVIDIA در مراسم معرفیاش از آن به عنوان پیچیدهترین مدار مجتمع وقت جهان یاد کرده بود.
GK110 یک پردازنده گرافیکی (GPU) است که در صنعت تراشهسازی NVIDIA توسعه یافته است
NVIDIA با عرضه کارت گرافیکهای GeForce GTX 780 Ti و Quadro K6000 فناوری GK110 را بهطور کامل در دو خانواده «جیفورس» و «کوادرو» پیاده کرد
و Tesla K20 اولین تراشه این شرکت بود که از مزایای GK110 بهره برده بود.
تراشه Tesla K40 تمام ویژگیها و امکانات GK110 را دارد و ۲۸۸۰ هسته پردازشی و ۱۲ گیگابایت حافظه RAM را فراهم میکند
که این مقدار حافظه در مقایسه با K20 به دو برابر افزایش یافته است
شرکتهای زیادی از جمله HP، از شتاب دهنده گرافیکی Tesla K40 در محصولات خود استفاده میکنند.

کارت گرافیک NVIDIA Tesla K80
تسلا در زمینه دیتاسنترهای پرشتاب، حرف اول را در دنیا میزند.
شتاب دهندههای NVIDIA Tesla K80 هزینههای دیتاسنترها را به شکل بینظیری کم میکنند
چرا که قادرند کارایی فوقالعادهای را در سرورهایی قدرتمندتر و با تعداد کمتر فراهم کنند.
آنها میتوانند توان عملیاتی را 5 تا 10 برابر افزایش دهند
و در عین حال نسبت به سیستمهایی که تنها مبنی بر CPU هستند میتوانند تا 50 درصد صرفهجویی را برای مشتریان فراهم کنند.
این کارت گرافیک محبوبترین کارت گرافیک دیتاسنتری است.
بیش از 400 اپلیکیشن پرمصرف و مهم از کارت گرافیکهای NVIDIA پشتیبانی میکنند، مخصوصا اپلیکیشن مهم HPC یا High Performance Computing
کارت گرافیک Tesla K80 با دو پردازنده گرافیکی GK210، جزء سریعترین محصول تولیدی شرکت NVIDIA محسوب میشود.
در تسلا K80، همان تکنولوژی موجود در کارتگرافیکهای GeForce NVIDIA به کار رفته است یعنی تکنولوژی کوپلر.
اما علاوه بر افزایش چشمگیر حافظه، بهینهسازیهای دیگری را نیز شامل میشود.
تراشه GK210 در بهبود مصرف برق و افزایش کارایی، نقش اساسی دارد
و فرکانس هسته آن در حالت پایه 562 مگاهرتز و در حالت Boost به 875 مگاهرتز میرسد.
کارت گرافیک تسلا K80 قادر است سرعتی معادل 8.74 ترافلاپس را تأمین کند.
این کارت گرافیک همچنین کارایی و پهنای باند دو برابری نسبت به نسل قبلیاش، K40 دارد
این کارت گرافیک در مجموع دارای 4.992 هسته پردازشی (حداقل و حداکثر فرکانس پردازندهها به ترتیب 562 و 875 مگاهرتز)،
24 گیگابایت حافظه GDDR5 از نوع ECC و پهنای باند 480 GBps است،
حداکثر مصرف برق 300 وات و درگاه ارتباطی اش PCI Express 3.0 x16 هستش
NVIDIA در این محصول از تکنولوژی Dynamic GPU Boost و قابلیت موازیسازی دینامیک استفاده کرده است،
که با افزایش سرعت پردازش و کارایی، نتایج بهتری برای کاربران حاصل میشود.
در این کارت ترکیبی از سریعترین شتابدهندههای پردازنده گرافیکی، مدل محاسبات موازی CUDA و مجموعهای از توسعهدهندگان نرمافزار وجود دارد.
بهینه شده برای سرور برای ارائه بهترین توان عملیاتی در دیتاسنتر شرکتهایی چون HP از K80 و K40 در سرورهای پرولیانت خود استفاده میکنند

کارت گرافیک NVIDIA Tesla M60
کارت گرافیک مدل Tesla M60 یک کارت گرافیک با پلتفرم Grid بوده که برای سیستم های دسکتاپ مجازی قابل استفاده است.
این کارت گرافیک از 32 کاربر پشتیبانی می کند و قادر است برنامه های کاربردی را به بالاترین سطح عملکرد گرافیکی را اجرا نماید.
این محصول از 16 گیگابایت حافظه GDDR5 از نوع ECC بهره برده و دارای 4096 هسته کودا است.
تعداد پردازنده گرافیکی 2 تا عدد است.
سیستم خنک کننده کولر خازنی

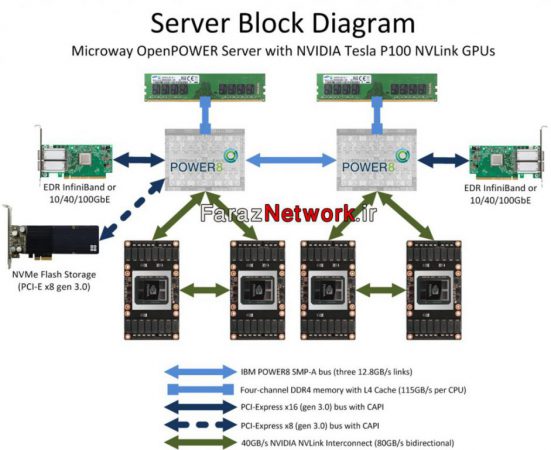
NVIDIA Tesla P100
TESLA P100 بر پایه معماری “پاسکال” تولید شده است.
P100 از 16 گیگابایت حافظه HBM2 برخوردار است که می تواند سرعت در اختیار گذاشتن اطلاعات به پردازنده را بسیار بالا ببرد.
لازم به ذکر است که این برای اولین بار است که یک پردازشگر تسلا از لیتوگرافی 16 نانومتری استفاده می کند
و مدل های گذشته عموما دارای لیتوگرافی 28 نانومتری بودند.
4 مگابایت حافظه کش L2 و 14 مگابایت حافظه Register File برای آن در نظر گرفته شده است.
در بخش توان محاسباتی:
-
- 5.3 ترافلاپ در حالت پردازش هایی 64 بیتی،
- 10.63 ترافلاپ در حالت پردازش های 32 بیتی،
کلاک GPU در حالت (Boost) برابر با 1408 مگاهرتز و در حالت پایه نیز 1328 مگاهرتز است.
حافظه نصب شده از فناوری ECC استفاده می کند که می تواند ضریب خطا را به خوبی کاهش دهد.
انویدیا از رابط NVLink استفاده کرده است و به همین علت پهنای باند آن به 160 گیگابایت بر ثانیه رسیده است.
P100 در اولین کاربرد خود، در داخل ابرکامپیوتر DXG-1 نصب شد.
این کارت گرافیک ها در سیستم های سرور، رندرینگ، پردازش های تحت شبکه و… مورد استفاده قرار گرفته و یکی از رقبای آن Fire Pro ها هستند.


AMD Radeon Pro V340
شتاب دهنده AMD Radeon Pro V340 در کلاس سرور، دارای 2 تراشه داخلی است.
این محصول به 32 گیگابایت حافظه گرافیکی HBM2 با فناوری Error Correcting Code یا تصحیح کننده خطا مجهز است.
این محصول از تکنولوژی 14 نانومتری بهره می برد و به گفته AMD سری V340 دارای ویژگی های امنیتی در سطح سازمانی است.
سامانه پر قدرت مجازی سازی (SR-IOV (Single Root I/O Virtualization به همراه AMD MX GPU بهترین ویژگی های رندر ابری را فراهم می سازند.
با توجه به ویژگی Integrated Encode Engine این شتاب دهنده امکان کدگذاری و کد گشایی فرمت های H.264 و H.265 را خواهد یافت.

کارت گرافیک FirePro S9300 X2
کارت گرافیک FirePro S9300 X2 به عنوان یک کارت گرافیک قدرتمند و نسبتا کم مصرف در سیستم های سرور استفاده می شود.
این محصول از 8 گیگابایت حافظه HBM به صورت دو انباشته 4 گیگابایتی بهره می برد
و با سیستم عامل های 64 بیتی لینوکس سازگاری کامل دارد.
بر اساس نسل سوم معماری GCN، این کارت گرافیک توانی برابر با 13.9 ترافلاپ در حالت FP32 دارد.
8192 پردازنده دو هسته ای.
کلاک حافظه می تواند به حداکثر نرخ 1 گیگابیت بر ثانیه دسترسی پیدا کند و پهنای باند آن نیز 8192 بیت است.
لازم به ذکر است که این ارقام حاصل جمع منابع هر دو GPU است که در یک کارت گرافیک ادغام شده اند.
فرایند ساخت نیز 28 نانومتری است.
این کارت گرافیک می تواند در سیستم های سرور به بهترین شکل ایفای نقش کند



کارت گرافیک سروری AMD FirePro W9100
این کارت گرافیک همانطور که از نامش نیز پیداست، در شاخه محصولات FirePro قرار می گیرد.
همانطور که می دانید پرداختن به مسئله پردازش های ابری و سرور بسیار مهم است
چراکه کمپانی ها برای تامین سخت افزارهای اصلی آن با یکدیگر در رقابت هستند.
یکی از دلایل مهم بودن این بخش هزینه بالای سخت افزارهای آن و سود سرشار است!
این کارت گرافیک از 32 گیگابایت حافظه اختصاصی برخوردار است
و از آنجایی که هدف اصلی آن در پردازش های 3D است، می توان انتظار زیادی از آن داشت.
AMD اعلام کرده است که این کارت گرافیک می تواند رندرهایی در دقت 4K را انجام دهد

قدرتمندترین کارت گرافیک AMD برای کارهای حرفه ای و سرور با 5 ترافلاپ قدرت پردازشی
- 16 گیگابایت حافظه گرافیکی GDDR5 با اینترفیس 512 بیت
- پهنای باند حداکثر 320 گیگابایت برثانیه،
- 44 هسته پردازش گرافیکی AMD (که با نام اختصاری GCN شناخته می شود)
- 64 پردازنده در هر GCN یعنی 2816 پردازنده در مجموع،
این قابلیت ها در کنار هم جمع شده اند تا قدرت پردازشی 5.07 ترافلاپ را روی یک کارت گرافیک فراهم کنند!
با وجود این میزان قدرت پردازشی، تنها 235 وات برق مصرف می کند
مقایسه با Tesla K40 با 12 گیگابایت حافظه گرافیکی GDDR5 که و قدرت پردازشی 4.29 ترافلاپس باید گفت که فوق العاده هستش.
AMD اذعان داشته که کارت S9150 تا 18 درصد نسبت به نسل های قبل خود از قدرت بالاتری برخوردار است.

نویسنده: مهندس عیسی رشوند
جهت مشاهده فیلم های آموزشی و ثبتنام دوره های آنلاین تعمیرات کامپیوتر و شبکه، بر روی این لینک کلیک نمایید.
مقالات مرتبط:
- بررسی نوسانات ولتاژی روترها (قسمت دوم)
- عیب یابی و رفع خرابیهای پرینتر
- راﻫﻨﻤﺎی ﻧﺼﺐ ﮐﻨﺘﺮل از راه دور
- عیب یابی و رفع خرابیهای مادربرد (1)
مقالات غیر مرتبط:






دیدگاهتان را بنویسید
برای نوشتن دیدگاه باید وارد بشوید.