بررسی کاربرد ITIL در سازمانها (قسمت اول)

بررسی کاربرد ITIL در سازمانها (قسمت اول):
هدف ITIL:
رسیدن به عملیات عادی و طبیعی در کمترین و کوتاه ترین زمان ممکن، با کمترین میزان تاثیر در تجارت یا کاربر، با صرف یک هزینه مقرون به صرفه است.
رخدادها ممکن است به دلایل مشخص و یا نامشخصی به وقوع بپیوندند
و نهایتا به منظور کنترل کردن مدیریت مشکلات (problem management) در Known Error Database – KeDB ثبت میشوند.
رخدادها و تغییرات
رخدادها نتایج مشکلات و خطاهای زیربناهای فنآوری اطلاعات هستند.
علت بروز رخداد ممکن است پیدا و روشن باشد و نیازی به سرمایه گذاری (از نظر زمانی و هزینهای) برای شناسایی علت بروز رخداد نباشد
و منجر به درخواست برای یک تعمیر، یک حضور فیزیکی در محل یا یک درخواست تغییر برای حذف خطا باشد.
جایی که یک رخداد مطرح میشود تا بصورت جدی و قاطعانه پیگیری شود
و یا چند پیشامد مشابه یک رخداد مشاهده میشود، یک مشکل میتواند به عنوان پاسخی برای حل همه موارد در سیستم ثبت شود
(همچنین ممکن است تا چند مشکل مشابه گزارش نشود، اصلا مشکلی هم ثبت نشود).
مدیریت یک مشکل از (فرآیند مدیریت یک رخداد) متفاوت است و معمولا توسط کارمندان متفاوت انجام میشود
و به همین دلیل توسط فرآیند مدیریت مشکلات کنترل میشود.
وقتی که یک مشکل شناسایی میشود و محیط مشکل پیدا میشود، مشکل یک “مشکل شناخته شدهٰ“ می شود.
هنگامیکه ریشه و علت بروز رخداد شناسایی می شود تبدیل به یک “خطای شناسایی شده” می شود
و نهایتا یک درخواست تغییر (Request For Change – RFC) ممکن است برای تغییر (اصلاح) سیستم یا رفع خطای شناسایی شده ایجاد شود.
این فرآیند توسط فرایند مدیریت تغییرات (Change Management) تحت پوشش قرار گرفته است.
توجه داشته باشید که درخواست یک سرویس اضافی به عنوان یک رخداد شناخته نمی شود و آن را یک درخواست تغییر (RFC) می نامند.
رخداد باعث بوجود آمدن یک سری فرآیند می شود که به اختصار در زیر به آن پرداخته ام
مديريت رخداد (Incident Management):
هدف مدیریت رخداد:
بازگرداندن عملیات سرویس دهی به شکل معمول و نرمال، در کمترین زمان ممکن و به حداقل رساندن اثرگذاری مضرات (ناسازگاری ها) در عملیات تجاری است.
عملیات معمول سرویس (Normal Service Operation) در اینجا به عنوان یک عملیات سرویس در محدودیت های توافقنامه سطح سرویس (SLA) تعریف می شود.
به زبان دیگر مدیریت رخداد یک بخش فرآیند از مدیریت سرویس فنآوری اطلاعات (ITSM – IT Service Management) است.
هدف اول این فرآیند، بازگرداندن عملیات به شکل سرویس دهی طبیعی و نرمال در کمترین زمان ممکن و به حداقل رسانیدن تاثیرات منفی آن (عدم سرویس دهی) در عملیات تجاری است.
(منظور از Incident هر اتفاقي است كه جزء كارهاي روتين يك سرويس نيست
و ممكن است باعث توقف در اجراي سرويس شود ويا كيفيت سرويس را كاهش دهد.
مدير اين فرآيند پردازش ها را نظارت ميكند،
تخصيص نيروها در لايه هاي مختلف اين فرآيند را تعيين ميكند،
از بروزرساني بانك اطلاعاتي اين فرآيند مطمئن است،
استفاده كارآمد و نگهداري از ابزارها را انجام ميدهد،
برنامه ريزي و گزارش دهي نيز از جمله وظايف اين مدير است.)
فرآیندهای اصلی مدیریت رخداد:
- شناسایی و ثبت رخداد
- طبقه بندی و پشتیبانی اولیه
- تحقیق و تشخیص
- رفع مشکل و بازیابی
- بستن رخداد
- مالکیت رخداد، بازدید، پیگیری و ارتباطات
مزایایی که از پیاده سازی یک فرآیند مدیریت رخداد شامل حال سازمان میشود عبارت است از:
مانیتورینگ پیشرفته، بدست آوردن کارایی در مقابل توافق سطح سرویس (SLA) برای بدست آوردن دقت.
- اطلاعات مدیریتی اصلاح شده درباره ظهور کیفیت خدمات
- استفاده بهتراز کارکنان که باعث کارایی بهتر میشود
- حذف رخدادهای نادرست یا گم شده (نادیده گرفته شده) و درخواستهای خدمات
- باز بینی اطلاعات پایگاه داده مدیریت پیکربندی (CMDB) با دقت و صحت بیشتر
- افزایش رضایت مشتری و کاربر
مديريت مشكلات (Problem Management):
هدف مدیریت مشکلات، حل دلیل اصلی رخدادها و پس از آن به حداقل رساندن تاثیرات منفی رخدادها و مشکلات موسسه است
که با توجه به خطاها در زیرساختهای IT ساخته شده ، و جلوگیری از رخداد دوباره، مربوط به این خطاست.
یک مشکل، یک دلیل نامعلوم و ناشناخته از یک یا چند رخداد است
و یک خطای شناخته شده، مشکلیست که به صورت موفقیت آمیز تشخیص داده شده. (CCTA)
یک خطای شناخته شده وضعیتی است که دلیل اصلی مشکل در آن به صورت موفقیت آمیز شناخته شده است
و گردش کاری مناسب روی آن انجام شده است.
مدیریت خطا با مدیریت رخداد متفاوت است.
هدف اصلی مدیریت مشکلات، پیدا و حل کردن ریشه اصلی مشکلات و جلوگیری از رخدادهای جدید است
ولی هدف مدیریت رخداد این است که سرویس را در سریعترین زمان ممکن به حالت نرمال باز گردانده شود.
فرآیند مدیریت مشکلات این هدف را دارد که تعداد و شدت رخدادها و مشکلات را روی تجارت کاهش دهد
و آن را در قالب مستندات گزارش داده تا در اولین و دومین مورد در help desk در دسترس باشد.
فرآیند پیش گیرانه، مشکلات را قبل از اینکه رخدادی روی دهد تعیین کرده و آنها را حل میکند.
این فعالیتها به شرح زیر است:
- تحلیل روند
- عملیات پشتیبانی هدف
- جمع آوری اطلاعات برای سازمان
فرآیند کنترل خطا یک فرآیند تکراریست تا خطاهای شناخته شده را تشخیص دهد
تا اینکه آنها با پیاده سازی موفق یک تغییر در کنترل فرآیند مدیریت تغییرات حل شود.
فرآیند کنترل مشکل قصد دارد که مشکلات را در یک راه موثر و کارا کنترل کند.
این فرآیند علت ریشه ای (root cause) رخدادها را مشخص کرده و آنها را به service desk معرفی میکند.
دیگر فعالیتها عبارت است از:
- شناسایی مشکل و ثبت آن
- دسته بندی مشکلات
- بررسی و تشخیص مشکل
تکنیک استاندارد برای مشخص کردن ریشه اصلی مشکل این است که از یک دیاگرام Ishikawa استفاده کنید،
همچنین مراجعه کنید به نمودار علت و معلول (cause and effect diagram)، نمودار درخت (tree diagram)، یا نمودار جناغی (fish diagram).
نمودار ایشیکاوا نتیجه نوعی از جلسه است که در آن اعضای یک گروه ایده های خود را برای بهبود یک محصول مطرح مینمایند.
برای حل مشکل، هدف پیدا کردن دلیل و تاثیرات یک مشکل است.
نمودار ایشیکاوا میتواند در یک meta-model تعریف شود.
اولا یک موضوع اصلی موجود است، که ما تلاش میکنیم که کدام backbone از نمودار را حل کنیم یا بهبود ببخشیم.
ارتباط بین یک علت و معلول یک ارتباط دوطرفه است.
مزایای انتخاب یک روش رسمی برای مدیریت مشکلات شامل موارد زیر است:
- کیفیت خدمات IT بهبود یافته و به مدیریت مشکلات کمک میکند که یک چرخه از کیفیت سرویس IT صعودی با سرعت بالا تولید شود.
سرویس قابل اطمینان با کیفیت بالا برای کاربران تجاری IT و همچنین برای بهره وری و دلگرمی فراهم کنندگان خدمات IT نیز مناسب است.
- کاهش حجم رخداد.
مدیریت مشکل در کاهش تعداد رخدادهایی که در جریان تجارت وقفه می اندازد سودمند است.
- راه حلهای دائمی و پایدار.
یک کاهش تدریجی در تعداد و تاثیر مشکلات و خطاهای شناخته شده به عنوان آنهایی که رفع شده اند همچنان رفع شده میمانند، وجود خواهد داشت.
- دانش سازمانی اصلاح شده.
فرآیند مدیریت مشکل بر مبنای یادگیری از تجارب گذشته استوار است.
فرآیند، داده های تاریخی را برای تشخیص روندها و وسایل پیشگیری خرابی و کاهش تاثیرات مضر خرابی، فراهم میکند
که این سبب بهبود بهره وری کاربر میشود.
- بهترین درجه رفع مشکل برای اولین مرتبه (better first time fix rate) در مدیریت مشکل این خصیصه را در Service Desk بهبود میبخشد.
این از طریق گرفتن، نگهداری و داشتن قدرت تشخیص رخداد و گردش کاری داده، در یک پایگاه داده دانش (Knowledge database) در دسترس در Service Desk در هنگام واقعه نگاری مشکل بدست می آید.
مديريت پيكربندي (Configuration Management):
جهت فراهم كردن يك مدل منطقي از زيرساخت IT با استفاده تز شناسايي، كنترل، نگهداري و تأييد نسخه تمام CI ها از لحاظ موجوديت آنها که اطلاعات راجع به موارد زیر را شامل می شود:
- سخت افزار
- نرم افزار
- مستندات
- پرسنل
مدیریت پیکربندی در اصل شامل 4 وظیفه ی اصلی می باشد:
- شناسایی (شناسایی همه ی اجزا و گنجاندن آنها در CMDB)
- کنترل (مدیریت همه اجزا و مشخص کردن مواردی که در پروژه قابلیت تغییر دارند.)
- وضعیت (ثبت وضعیت تمام موارد در CMDB و نگهداری از اطلاعات مربوطه)
- بازبینی (بررسی اطلاعات CMDB برای اطمینان از صحت و دقت آنها)
مديريت تغييرات (Change Management):
اين فرآيند وظيفه تهيه روالهايي بمنظور تست، كنترل و نظارت و مديريت پياده سازي درخواست تغييرات (RFC) ها را بعهده دارد.
توسط اين فرايند:
مديريت درخواست تغييرات،
ارزيابي تغييرات مجوز دهي به تغييرات،
مديريت پياده سازي تغييرات و جلوگيري از تغييرات بدون مجوز،
كاهش قطعي سرويس و هماهنگي در ساخت و پياده سازي
و تست تغييرات اعمال شده در سرويس ها، انجام ميپذيرد.
هدف مدیریت تغییرات این است که مطمئن شود که متدها و روشهای استاندارد شده برای اداره کردن موثر تمام تغییرات استفاده شود،
برای اینکه تاثیرات سوء رخدادهای حاصل از تغییرات حداقل شده و برای اینکه عملیات روز به روز بهبود یابد.
یک تغییر معادل است با “یک رویداد که باعث یک یا چند وضعیت جدید در آیتمهای پیکربندی (CI) شود”.
اهداف اصلی مدیریت تغییرات به شرح زیر است:
- حداقل کردن قطع سرویسها
- کاهش فعالیتهای فرسوده شده
- بکارگیری اقتصادی از منابع درگیر با تغییرات
فواید خاص یک سیستم مدیریت تغییرات تاثیرگذار شامل موارد زیر است:
- در یک راستا قرار دادن خدمات IT با نیازهای تجاری به بهترین نحو
- دید توسعه یافته و ابلاغ تغییرات به کارکنان تجاری و پشتیبانی خدمات
- برآورد ریسک اصلاح شده
- کاهش تاثیر نامناسب تغییرات روی کیفیت خدمات و توافقات سطح سرویس (SLA)
- ارزیابی بهتر هزینه تغییرات احتمالی قبل از اتفاق افتادن
- تغییرات معدود که بر اثر کهنه شدن به وجود می آید همراه با توانایی بیشتر برای انجام راحتتر در هنگام لزوم
- مدیریت مشکل و دسترس پذیری وسعت یافته در حین استفاده از اطلاعات ارزشمند مدیریتی مربوط به تغییرات انباشته شده در حین فرآیند مدیریت تغییر
- افزایش بهره وری کاربران – به خاطر قطع کمتر و کیفیت بالاتر خدمات
- افزایش بهره وری پرسنل کلیدی به خاطر نیاز کمتر به منحرف شدن از وظایف برنامه ریزی شده برای پیاده سازی تغییرات فوری یا تغییرات نادرست قدیمی
- توانایی بالاتر برای تحلیل تغییرات با حجم بالا
- درک تجاری بهتر از IT به خاطر کیفیت خدمات بهتر و یک روش حرفه ای
مدل فرایند پشتیبانی سرویس ITIL
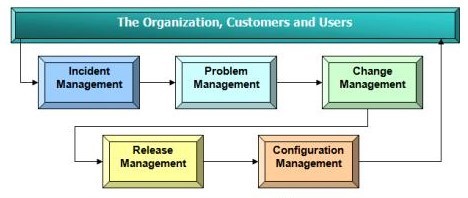
ارائه خدمات (Service Delivery)
ارائه خدمات شامل سرویس مدیریت ITIL است.
فرایند ارائه خدمات:
- تعریف واضح از محتوای خدمات
- توضیح واضح در مورد نقش و مسئولیت های مشتری و خریدار، تعریف کاربران (آنهایی که از خدمات استفاده می کنند) و ارائه دهندگان خدمات
- مجموعه ای از انتظارات کیفیت، در دسترس بودن و به هنگام بودن خدمات
فرآیندهای ارائه خدمات به تعریف نحوه اندازه گیری نتایج خدمات با معیارهای معنی دار و بهبود مستمر خدمات کمک می کند.
ارائه خدمات راهی برای حداکثر کردن سود شرکت از طریق گسترش خدمات به شرکت های بزرگ است.
اجزای سازنده ارائه خدمات عبارتند از:
مديريت سطح خدمات (Service level Management):
اين فرآيند تنها اولين و تنها نقطه تعامل مشتري با سازمان IT مي باشد.
در اين فرآيند نيازمندهاي خدمت (سرويس) مورد نياز مشتري وحدود كيفيت آن تشخيص داده شده تنظيم ميگردد و توافقات بعمل آمده مستند مي شود.
كنترل و بهبود مستمر كيفيت خدمات هم بعهده اين مديريت است.
وظيفه اصلي اين فرآيند:
تبديل (SLR (Service Level Requirement به (SLA (Service Level Agreement از طريق ميزمذاكره ميان مشتري (Customer)، مدير فرآيند (service Level Manager) و تهيه كننده سرويس (Provider) ميباشد.
همچنين ارائه برنامه هاي بهبود مستمر از ديگر وظايف اين فرآيند مي باشد.
تعدادی از فرآیندهای کسب و کار عبارتند از:
- مرور خدمات موجود
- مذاکره با مشتریان
- بررسی زیر بنای ارتباطات ارائه دهندگان
- تولید و نظارت موافقتنامه سطح خدمات (SLA)
- اجرای پروژه های خدمات و فرایندهای بهبود سیاست
- ایجاد اولویت
- برنامه ریزی برای رشد سرویس
- رسیدگی به حسابداری و بررسی هزینه های خدمات و بهبود بخشیدن این هزینه ها
مديريت پايايي خدمات (Availability management):
اين فرآيند تضمين كننده ی قابليتهاي زيرساخت IT، سرويس هاي IT و سازماني كه ارائه خدمات مي نمايند،
است و مي تواند با روشي قابل اعتماد و معقول به لحاظ هزينه ،سطوحي از پايايي را فراهم كند كه انتظارات كسب وكار را تأمين نمايد.
اهداف:
برای درک الزامات دسترسی به کسب و کار و پیش بینی، اندازه گیری برنامه ریزی، نظارت و تلاش در جهت بهبود مستمر.
- بهینه سازی زیر ساخت های فناوری اطلاعات برای ارائه مقرون به صرفه و سطح پایدار از دسترس به منظور فعال کردن کسب و کار و جلب رضایت مشتری.
فعالیت ها:
- تعیین نیازهای در دسترس مشتریان
- پشتیبانی از وظایف کسب و کار (VBF)
- طراحی برای دسترسی
- مشخص کردن قطعات مورد نیاز خدمات در دسترس
- شناخت و بهبود زیرساخت
- تجزیه و تحلیل و مدیریت ریسک
شاخص کلیدی عملکرد:
- کاهش درصد در دسترس نبودن خدمات و اجزای سازنده
- درصد افزایش قابلیت اطمینان سرویس و قطعات
- متوسط زمان برای تعمیر (MTTR)
- متوسط زمان بین حوادثی خدمات (MTBSI)
- متوسط زمان بین خرابی (MTBF)
مديريت استمرار (Continuity Management):
وظيفه اين فرآيند پشتيباني از تداوم كسب و كار سازمان و در برگيرنده مسئوليت سرويس هاي IT است كه نياز به برنامه ريزي هاي فوريتي دارند.
اين فرآيند بايد تضمين كننده اين موضوع باشد كه سازمان قادر است سرويس هاي ضروري خود را در مواقع اضطراري، به حالت نرمال و عملياتي بازگرداند.
مدیریت استمرار شامل مراحل زیر می باشد:
- کار با BCM و مدیریت سطح خدمات (SLM) برای تعیین پتانسیل ها و مسائل مورد نیاز از طریق بهبود کسب و کار
- انجام ارزیابی ریسک (معروف به تحلیل خطر و خطرپذیری) برای هر یک از خدمات، برای شناسایی دارایی، تهدیدها، آسیب پذیری و اقدامات متقابل برای هر سرویس.
- بررسی گزینه هایی برای بازیابی
- تولید طرح احتمال و قوع (پیاده سازی و تست تکنیک های پشتیبان و بازیابی و همچنین مذاکره و عقد قرارداد برای ایجاد جایگزین بهتر)
- آزمون، مرور و تجدید نظر در طرح به طور مرتب
(تداوم مدیریت / بازیابی / تداوم کسب و کار)
مديريت ظرفيت (Capacity management):
اين فرآيند تضمين كننده اين موضوع است كه در تمامي زمانها، با روشهاي مناسب و معقولي به لحاظ هزينه، حجم قابل قبولي از ظرفيت هاي IT سازمان به منظور تأمين اهداف و نيازهاي جاري و آينده كسب و كاري در دسترس مي باشد.
مراحل انجام کار:
- مقدمه
- برنا مه ریزی فرایند های مدیریت ظرفیت
- فعالیت های مربوط به فرایند ها
- هزینه ها، فواید و مشکلات احتمالی
- برنامه ریزی وپیاده سازی
- چکیده ایی از فرایند مدیریت ظرفیت
- واسط ها با پروسه های SM
مدیریت ظرفیت شامل موارد زیر می باشد:
- نظارت بر عملکرد (مانیتورینگ، تجزیه و تحلیل، تنظیم و اجرای تغییرات لازم در بهره برداری از منابع)
- کاربرد sizing مورد نیاز برای اطمینان از سطوح خدمات
- تقاضا مدیر عامل برای محاسبه ی منابع ، که نیاز به درک درستی از اولویت های کسب و کار دارد (پیش بینی منابع)
- پیش بینی تقاضا
- ذخیره سازی اطلاعات مدیریت ظرفیت
- ساخت یک طرح با توجه به ظرفیت بهره برداری مدارک فعلی و همچنین هزینه های پشتیبانی برای برنامه های کاربردی جدید و یا انتشار آن ها.
مديريت مالي براي سرويس هاي (IT (Financial Management:
اين مديريت فرآيندي براي بودجه بندي، حسابداري و شارژ هزينه هاست.
مهمترين هدف اين فرآيند اين است كه به روشي معقول از لحاظ هزينه، منابع و دارايي هاي خدمات IT مديريت شوند.
وظایف:
- نظارت بر همه هزینه های فناوری اطلاعات
- بودجه بندی (بودجه برای اطمینان از وقایع برنامه ریزی شده ی در دسترس)
- توسعه سیستم حسابداری IT
- ایجاد شارژ جدید
- ارائه اطلاعات دقیق مالی برای طرح های پیشنهادی
- تأثیر استفاده از فناوری اطلاعات برای افزایش دارایی هایی که سرمایه گذاری شده است (از طریق سیستم های chargeback)
- پیگیری هزینه های جاری در مقابل بودجه
- مدیریت عملیات
(مدیریت مالی نقش کلیدی پروژه ها را بر عهده دارد.)
مدل فرایند تحویل سرویس ITIL
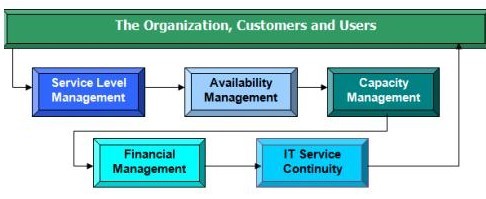
جهت مشاهده دوره های مدیریت و امنیت اطلاعات بر روی این لینک کلیک نمایید.
جدیدترین اخبار ثبت نام کلاس های آنلاین مجموعه فراز نتورک را در صفحات اجتماعی دنبال کنید.
نویسنده: مهندس علیرضا رشوند





دیدگاهتان را بنویسید
برای نوشتن دیدگاه باید وارد بشوید.